Is privacy a privilege or a fundamental right? In our increasingly digital world, this question has moved from philosophical debate to urgent practical concern. Let’s explore why digital privacy matters and how it connects to broader human rights principles.
Privacy in International Law
The Universal Declaration of Human Rights, adopted by the United Nations in 1948, includes privacy as a fundamental right. Article 12 states: “No one shall be subjected to arbitrary interference with his privacy, family, home or correspondence.” This was written long before the internet, but its principles remain relevant.
The International Covenant on Civil and Political Rights (1966) reinforced this, declaring that everyone has the right to protection against arbitrary or unlawful interference with their privacy. Many countries have incorporated these principles into their constitutions and laws.
Why Privacy Matters
Privacy isn’t about having “something to hide.” It’s about having control over your personal information and how it’s used. Think about it this way: you probably close the bathroom door even though you’re not doing anything illegal. Privacy is about boundaries, dignity, and autonomy.
In the digital realm, privacy protects several important interests. It allows us to explore ideas without judgment, develop our identities without constant surveillance, and communicate freely without fear of retribution. It creates space for dissent, creativity, and personal growth.
The Digital Age Challenge
Digital technology has created unprecedented challenges for privacy. Our phones track our locations. Our searches reveal our interests, concerns, and questions. Our purchases, medical records, and communications all generate data trails that can be collected, analyzed, and used in ways we never intended.
This isn’t hypothetical. Companies build detailed profiles of our preferences and behaviors. Governments collect metadata on communications at massive scales. Data brokers compile and sell personal information. All of this happens largely invisibly, without meaningful consent or control.
The Chilling Effect
When people know they’re being watched, they change their behavior. Researchers call this the “chilling effect.” Studies show that people search for less controversial topics, share fewer opinions, and engage in more self-censorship when they know they’re being monitored.
This has profound implications for free speech and democracy. If people can’t research sensitive topics, communicate privately with journalists, or organize politically without surveillance, we lose something essential to a free society. Privacy and freedom of expression are deeply interconnected.
Privacy and Other Rights
Privacy supports many other fundamental rights. Freedom of association depends on being able to join groups without government surveillance. Freedom of thought requires space to develop ideas without external judgment. Political participation needs confidential communication between activists and organizers.
For vulnerable populations, privacy can be literally lifesaving. Domestic abuse survivors need privacy to seek help without their abusers discovering their plans. LGBTQ+ individuals in hostile environments need privacy to explore their identities safely. Whistleblowers need privacy to expose wrongdoing without facing retaliation.
The Surveillance Capitalism Model
Much of the internet operates on what Harvard professor Shoshana Zuboff calls “surveillance capitalism” – business models based on collecting maximum data about users to predict and influence their behavior. This creates structural incentives to undermine privacy.
When privacy becomes a luxury good – something you can only have if you pay for premium services or have technical expertise to protect yourself – it ceases to function as a right. Rights shouldn’t depend on wealth or technical knowledge.
Legal Protections Worldwide
Different regions have taken different approaches to protecting digital privacy. The European Union’s General Data Protection Regulation (GDPR) gives individuals significant control over their personal data. California’s Consumer Privacy Act provides similar protections at the state level.
However, many countries lack comprehensive digital privacy laws. Others have laws on the books but weak enforcement. And even strong privacy laws struggle to keep pace with rapidly evolving technology.
Technical Tools as Rights Protection
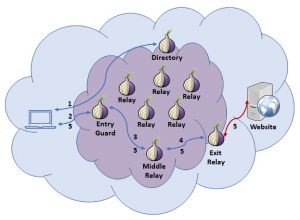
This is where privacy-enhancing technologies become important. Tools like encryption, Tor, and anonymous communication systems aren’t just about technology – they’re about enabling the exercise of fundamental rights in digital spaces.
When legal protections are insufficient or governments themselves pose privacy threats, technical tools become crucial. They create spaces where privacy exists regardless of the legal or political environment.
Balancing Privacy and Other Interests
Privacy isn’t absolute. It must be balanced against other legitimate interests like public safety, national security, and law enforcement. The question is how to strike that balance appropriately.
Many privacy advocates argue that current systems have swung too far toward surveillance. They point out that mass collection of data on everyone is different from targeted surveillance of individuals suspected of wrongdoing. The former treats everyone as potential suspects; the latter respects the presumption of innocence.
What Students and Researchers Should Know
Understanding privacy as a human right helps frame technical discussions in their broader context. When we talk about encryption protocols, anonymous networks, or data protection regulations, we’re really talking about how to preserve fundamental freedoms in the digital age.
This perspective is valuable for computer science students building the next generation of systems, policy students considering regulatory approaches, and anyone interested in digital rights. Technology choices have human rights implications, and human rights principles should inform technology design.
The Path Forward
Protecting digital privacy requires action on multiple fronts: better laws and regulations, privacy-respecting technology design, education about privacy risks and tools, and cultural recognition of privacy’s importance.
As individuals, we can make privacy-conscious choices about which services we use and how we share our information. As citizens, we can advocate for stronger privacy protections. As students and researchers, we can develop better technical solutions and study privacy’s social impacts.
Digital privacy isn’t just a technical problem or a legal question – it’s a fundamental human right that shapes the kind of society we live in. Recognizing this helps us approach privacy challenges with the seriousness they deserve.